Statistics is the study of the collection, analysis, interpretation, presentation, and organization of data. Statistics is a vast subject but we will keep it simple for Class 8 students.
In Statistics, we have to first learn the collection and Tabulation of data. It is all about data and then using that data to extract inferences.
Key Terms to Understand
Data: The word ‘data’ means information in the form of numerical figures or a set of given facts. is a set of values of qualitative or quantitative variables.
i) The marks obtained by 

ii) However, a collection of colors like Red, Blue, Green would be qualitative data something that generally cannot be measured with numerical results.
Raw or Ungrouped Data: The data obtained in original form is called raw data or ungrouped data. Clearly, the data shown above is a raw data. Normally, when we collect data, we will get raw data.
Group Data: For the sake of convenience (in study and comparison), we may condense the raw data into classes or groups. Such a presentation is known as grouped data.
Array: An arrangement of raw numerical data in ascending order of magnitude is called an Array. Example:

Tabulation or Presentation of Data: Arranging the data in the form of tables in condensed form is called as the Tabulation or Presentation of data.
Variable: A quality which is being measured in an experiment or survey is called a variable. Thus, age of students in a class, monthly income in an office, number of children in the residing in a locality, etc. are the examples of variable
Variate: A particular value of a variable is called variate.
Observation: Each numerical figure in a data is called observation.
Frequency: The number of times a particular observation occurs is called its frequency.
Frequency distribution: The tabular arrangement of data showing the frequency of each observation is called a frequency distribution.
Frequency Distribution of Ungrouped Data
Let’s use the following data to learn Frequency distribution.
Data: 
Step 1: Arranging the above data in ascending order, we get:

Step 2: Organize the data in frequency distribution. In simple terms, what it means is the number of times the same data appears.
Thus, we may prepare a frequency table as under:
| Number of children | Number of Families (Frequency) |
 |
 |
 |
 |
 |
 |
|
|
|
|
 |
|
Grouped Frequency Distribution: When you have large data set, the above frequency distribution might be more cumbersome. In such scenarios, we can simplify the data by grouping it in groups.
Inclusive Form:
Let’s say for the above data, we put them in different grouping or groups or class interval such as 
Here 


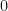

Here also you will follow the same steps 1 and 2. Thus, the above frequency distribution may be presented in inclusive form as under:
|
Class Interval |
Frequency |
|
|
|
|
|
|
 |
|





Exclusive Form:
If we do the same thing, but instead of inclusive, we have exclusive classes.
Here 


Here also you will follow the same steps 1 and 2. Thus, the above frequency distribution may be presented in exclusive form as under:
|
Class Interval |
Frequency |
|
|
|
|
|
|
|
|
|
 |
|






Class-interval: each group into which the raw data is condensed is called a class-interval. Each class is bounded by two figures, which are called class limits. The figure on left side called lower limit and figure on right side is called as upper limit of the class.
Thus
Class-boundaries: In an exclusive form the lower limits and upper limits are known as class boundaries.
Thus, if the boundaries of the class 





Class-size: Difference between true upper limit and true lower limit is called the class size.
Class Mark or Mid-value:

Thus the class mark of 

Range: The difference between the maximum value and the minimum value of the observations is called its range.
Graphical Representation of Statistical Data
The tabular representation of data is an ideal way of presenting them in a systematic manner.
However, to make the data more noticeable, or easily understandable, we use pictorial representation of the data. Example is a like a bar graph, or a line diagram etc. Once we represent the data in a graphical manner, it is easier to compare the data, see the trend within the data set.
Bar Graph (Or Column Graph)
A bar graph is a pictorial representation of numerical data in the form of rectangles (or bars) of uniform width and varying heights.
These rectangles are drawn either vertically or horizontally, keeping equal space between them.
How to Draw a Bar Graph?
Step 1. Take a graph paper. Draw the 

Step 2. Mark points at equal intervals along the
Step 3. Choose a suitable scale on that scale determine the height of the bars for the given numerical values. The height of a column represents the frequency of the corresponding observation. This is the number of “Families” or “Frequency”. In our example, there are 4 families that have 1 Child.
Step 4. Mark off these heights parallel to the
Step 5. On the
So if we were to plot bar graph for figure 1, we will get the following:

Discover more from ICSE / ISC / CBSE Mathematics Portal for K12 Students
Subscribe to get the latest posts sent to your email.